一、一个离线数仓的架构介绍
通过之前的系列文章的介绍,数仓是面向主题、集成、相对稳定的、反映历史变化的数据集合,通常用于支持管理决策。因此,离线数仓需要实现对数据的汇总、对数据的处理与分析两大部分的工作。这里,通过一个通用的离线数仓的架构,来进一步介绍,离线数仓是如何实现上述的两个大功能模块的。
首先,将架构图奉上。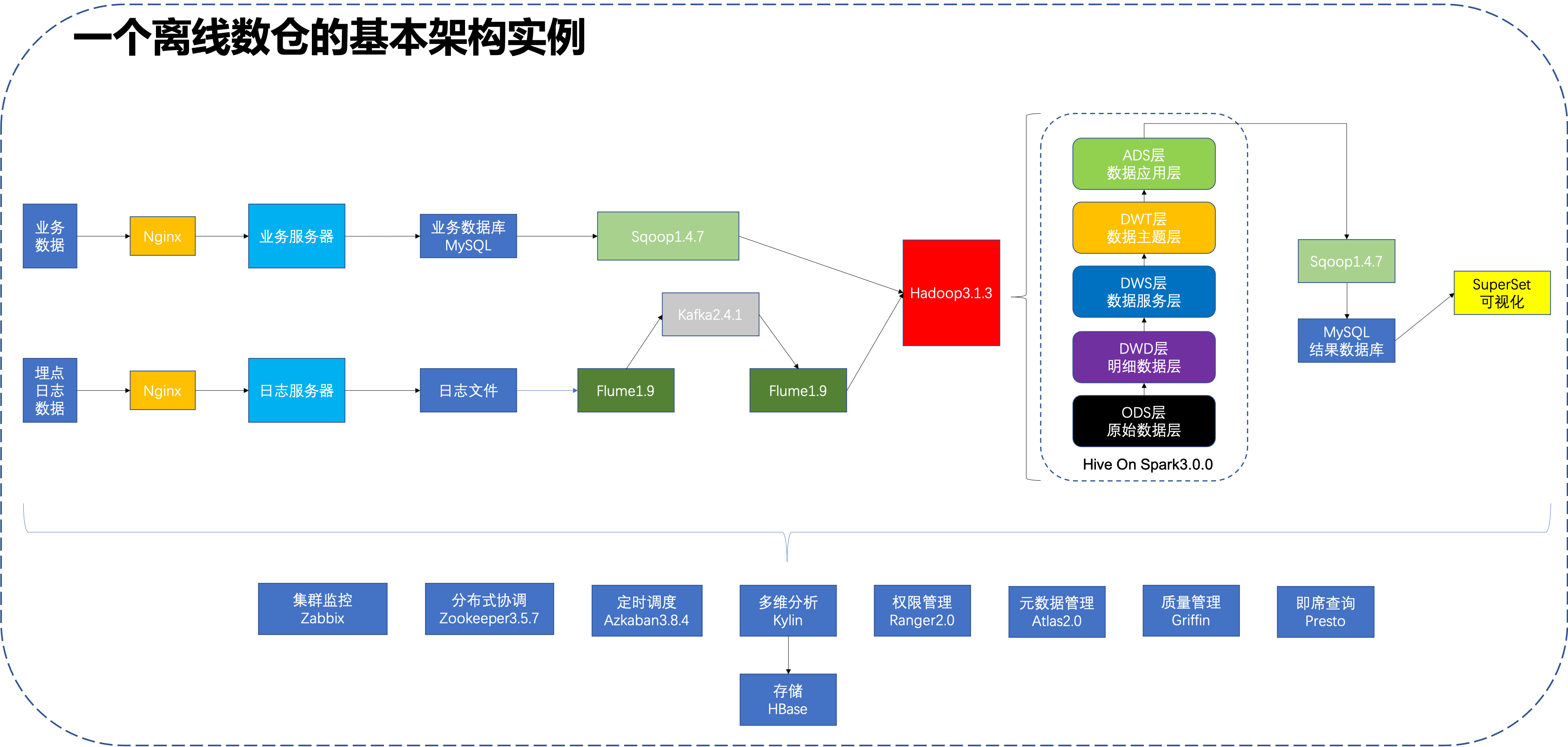
在一般情况下,业务数据和日志数据是一个公司最重要也是最活跃的两种数据类型。在上述架构图中将数据划分为业务和埋点日志两个部分,均有专门的服务器对其进行管理。业务数据通过业务服务器保存至关系型数据库中,埋点日志数据保存在文件中。
Apache Flume是一个分布式的、可靠的、可用的,从多种不同的源收集、聚集、移动大量日志数据到集中数据存储的系统,说白了就是一个监控器,它的作用是监控日志文件,当日志文件中有新内容产生后,会通过框架,读取新增内容,并通过其内部的处理逻辑,按照既定的规则写入目标系统中。
Apache Kafka是一个消息系统,将上游涌入的数据通过消息队列技术存储至数据管道中,直到下游对其消费完毕,该框架起到了对数据进行削峰的作用。
因此,在架构中,日志文件产生后,Flume会立即监控到,并针对其中的内容进行读取,将数据传输给Kafka。同时监控Kafka的Flume监控到Kafka存在数据后,将会立即读取Kafka的数据并将其数据写入至HDFS中。这里使用Kafka的目的就是为了对数据起到削峰的作用,确保上下游能够协调一致,避免数据洪峰时,下游消费不及时导致数据丢失等情况的发生,至于其中某个框架启动失败会导致什么结果等问题,在接下来会有讨论,这里不展开细讲。
Apache Sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具。可以通过Sqoop把数据从数据库(比如MySQL, Oracle)导入到HDFS中;也可以把数据从HDFS中导出到关系型数据库中。
在架构中,每天将业务数据通过Sqoop框架定时导入至HDFS中。
两类数据均存储至HDFS中后,Hive将会开始进行数据处理工作,这里就涉及到之前提出的数仓分层的概念,我们来复习一下。
| 层级名称 | 解释 | 要求 |
|---|---|---|
| ODS(Operation Data Store) | 原始数据层 | 存放原始数据,要求对数据不做任何处理,保持数据原貌。 |
| DWD(Data Warehouse Detail) | 明细数据层 | 对ODS层做数据清洗(去除空值、脏数据等),维度退化、脱敏等。粒度是一行信息代表一次行为,例如一次下单。 |
| DWS(Data Warehouse Service) | 服务数据层 | 以DWD为基础,按天进行轻度汇总。粒度是一行信息代表一天的行为,比如一天内下单的次数。 |
| DWT(Data Warehouse Topic) | 数据主题层 | 以DWS为基础,按主题进行汇总。粒度是一行信息代表累积的行为,例如用户层注册那天开始至今一共下了多少单。 |
| ADS(Application Data Store) | 数据应用层 | 为各种统计报表提供数据。 |
最后,Sqoop会将ADS层的分析结果数据再导入业务数据库中,并通过SuperSet框架进行可视化展示。
以上就是一个基本的离线数仓框架,但这些还不够。
我们可以发现,除了上面说的这些之外,在架构图的下方,有很多其他的框架对离线数仓的功能进行了补充和完善,其中涉及到即席查询、集群监控、定时调度、权限管理、元数据管理、质量监控等各个方面的内容,在后续会逐个进行讲解,这里将一个离线数仓的架构进行一个引入,在后续的文章中会进行详细的分析。
二、有关数仓的两个问题
1、数仓为什么要分层?
(1)把复杂的问题简单化。在当下,数据呈现的特点是无规律,体量大。因此,为了能够更好地管理以及利用数据创造价值,应根据当下业务需求,将复杂的任务分解成多层完成,每一层仅处理简单的任务,也方便在数据出问题时定位问题。
(2)减少重复开发。规范的数据分层,能够通过中间层的数据,减少极大地重复计算,增加一次计算结果的复用性。
(3)隔离原始数据。不论是数据异常还是数据的敏感性,都使得真实地数据与统计的数据解耦。
2、数据集市是什么?
数据集市,英文是Data Market。它是一种微型的数据仓库,它通常具有更少的数据, 更少的主题区域,以及更少的历史数据,是一种部门级别的数据仓库,一般只为某个局部范围内的管理人员服务。
三、数仓理论
1、范式理论
1.1 范式的概念
(1)定义:范式就是设计一张数据表的结构应符合的标准级别、规范与要求。
(2)优点:降低数据的冗余性;缺点:获取数据时,需要通过join拼接最后的数据。
(3)分类:第一范式、第二范式、第三范式、巴斯-科德范式、第四范式、第五范式
1.2 函数依赖
函数依赖有三种依赖关系,分别是完全函数依赖、部分函数依赖以及传递函数依赖。
- 完全函数依赖:通过AB能得出C,但AB单独不能得出C,从完全依赖于AB。
- 部分函数依赖:通过AB能得出C,通过A也能得出C或者通过B也能得出C,C部分依赖于AB。
- 传递函数依赖:通过A得到B,通过B得到C,但是C得不出A,那么C传递依赖于A。
1.3 三范式区分
(1)第一范式:属性不可分割。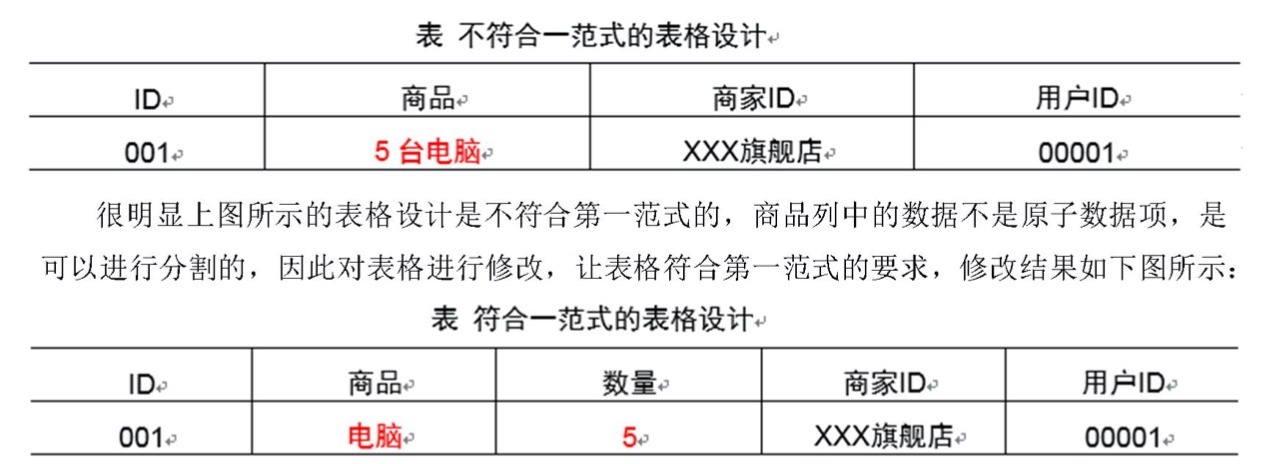
(2)第二范式:不能存在部分函数依赖。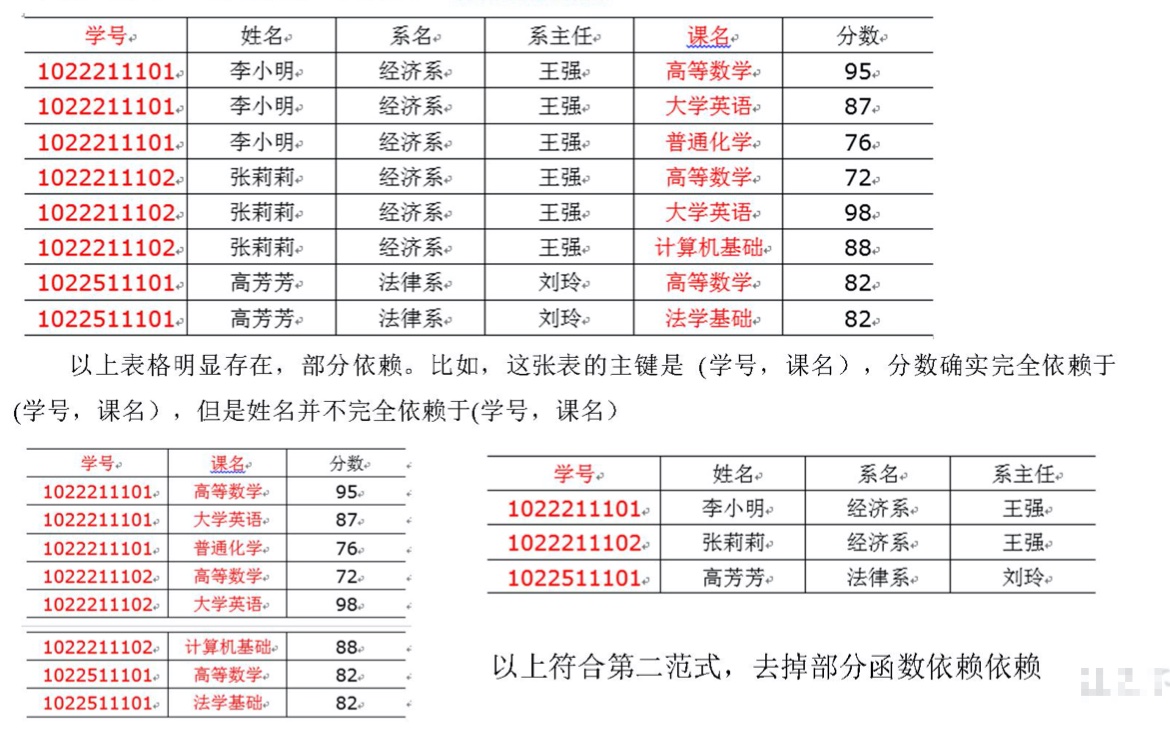
(3)第三范式:不能存在传递函数依赖。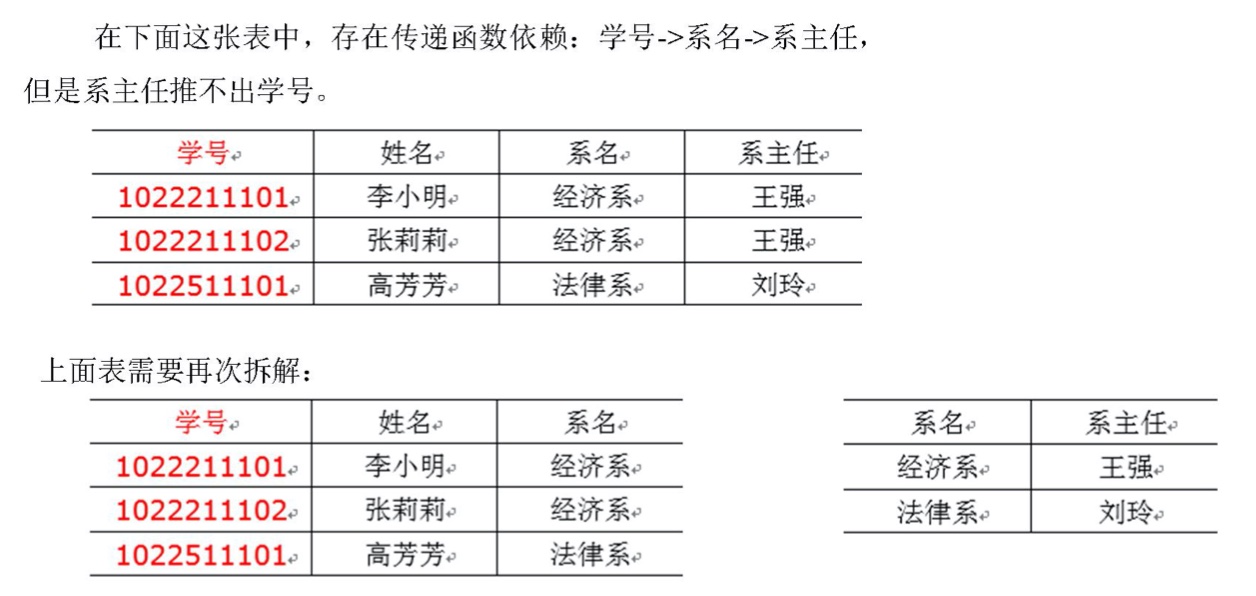
2、关系建模与维度建模
(1)关系建模:点我跳转~
(2)维度建模
维度建模有三种模型:星型模型、雪花模型和星座模型。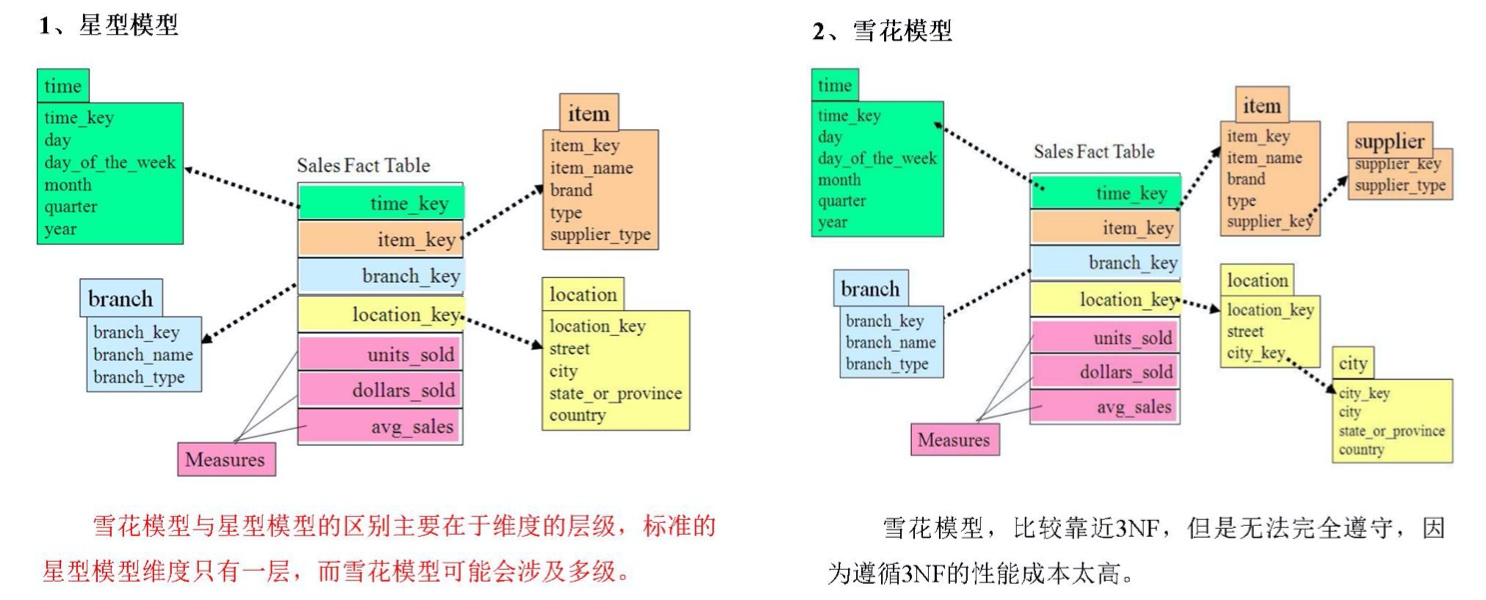
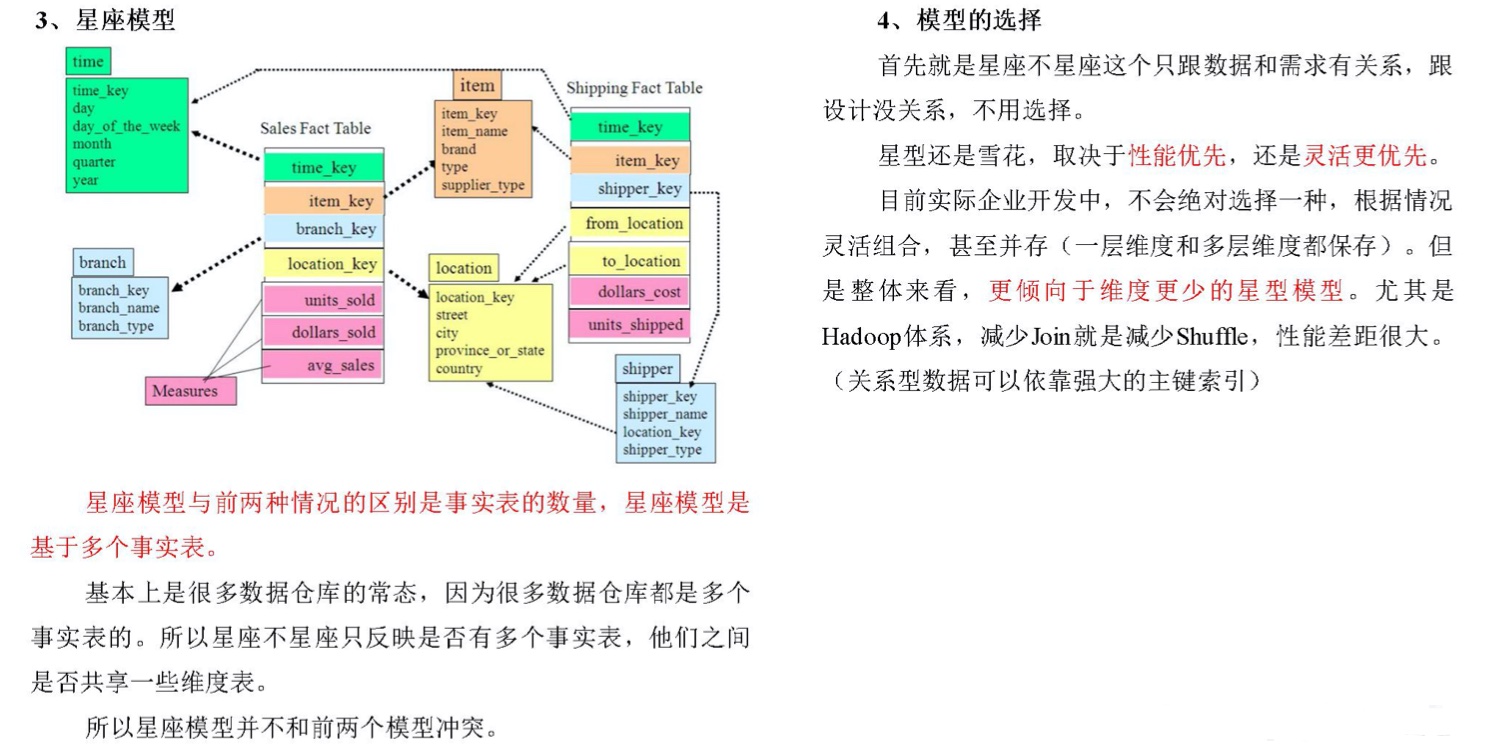
3、维度表和事实表【重要】
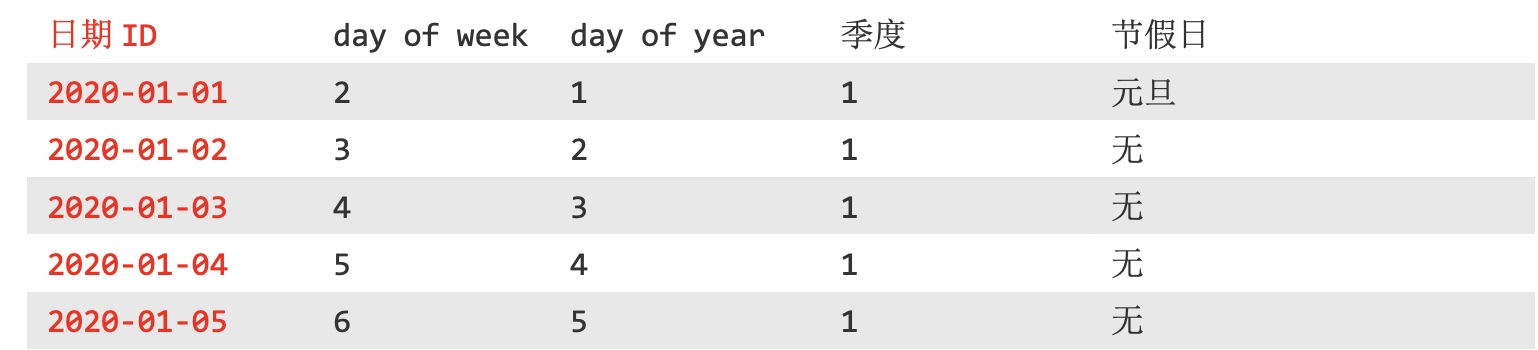
(1)维度表
- 定义:一般是对事实的描述性信息,每一张维度表对应现实世界中的一个对象或者概念。例如:用户、商品、日期、地区等。
- 维度表的特征:维度表范围很宽(具有多个属性、列很多);跟事实表相比,行数相对较小,通常<10w条;内容相对固定:编码表。
- 例子
(2)事实表 - 定义:事实表中的每行数据代表一个业务事件,例如:下单、支付、退款、评价等。“事实”这个术语表示的是业务事件的度量值(可以统计的次数、个数、金额等)。每个事实表的行包括:具有可加性的数值型的度量值、与维度表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维度表之间多对多的关系。
- 一个例子:张三在2020年11月11日于京东购买了一台价值1万元的苹果MacBook pro 15.2寸笔记本电脑。维度表:时间、用户、商品、商家。事实表:1万元、1台。
- 特征:非常大、内容相对较窄,列数少,主要是外键id和度量值、经常发生变化。每天新增很多数据。
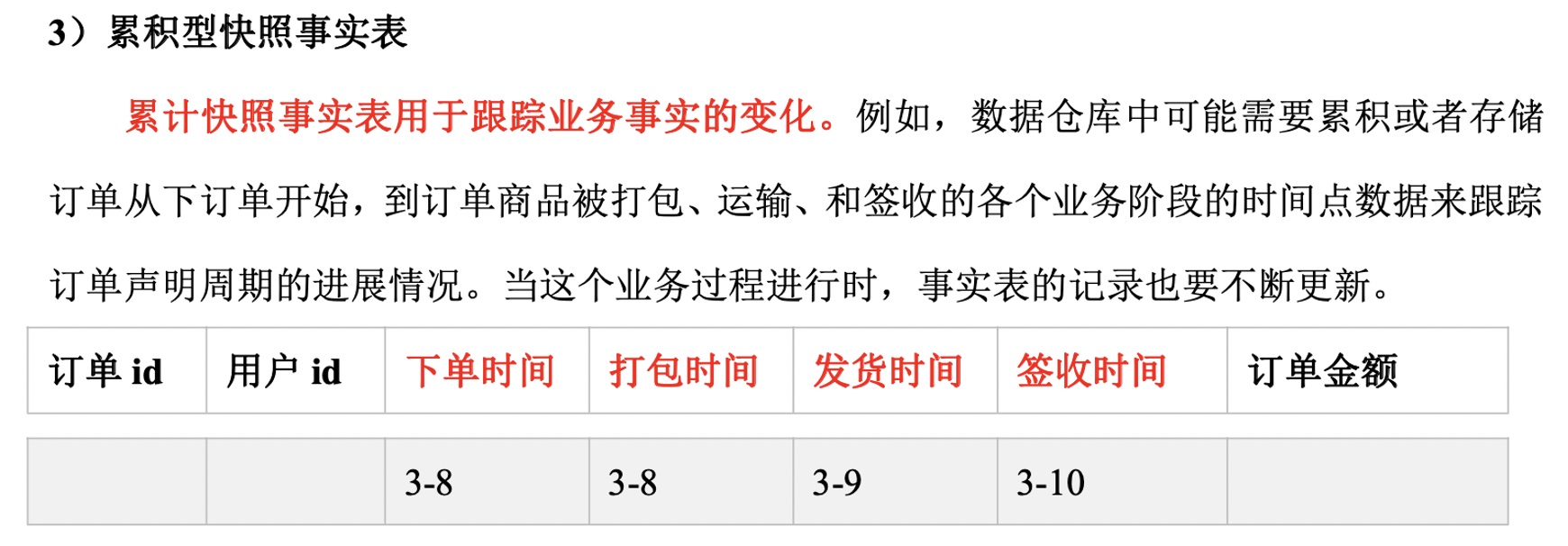
- 类型:事务型事实表、周期型快照事实表、累积型快照事实表